概要
ケータイ、鍵、道具。「あれって、どこいった?」を解消するインタフェースをプロトタイプしました。
「〇〇〇は、どこ?」と声をかけると、そのものがある場所に優しく光を当てて場所を教えてくれます。
映像中では、Alexaと連携しているように描いていますが、プロトタイプでは実際には、Google Speech APiを用いて、テキスト化された発言からキーワードを抽出し、光の照射を開始するトリガーとしています。
実験の背景
例えば、ユーザーの動作とプロジェクションの内容が連動するような、実空間と連動したインタフェース制作を手がける中で、物自体にセンサーを仕込む手法、再帰性反射材とIRカメラを組み合わせる手法、3D深度カメラを利用する手法、IRカーテンで指などのユーザーの動作を取得する手法などなど、過去、様々な認識手法を試みてきました。
特別なセンサーを購入したり、物へ特別な加工をせずに、インタラクションをトリガーさせるために、カメラを使った画像認識による方法を試行錯誤しています。
カメラからの画像を用いたパターンマッチによる物体検出では、光の変化などに弱く環境依存度が高く、更に新しい手法を求めているときに、AIによる物体検出とトラッキングを用いて対象物の状態を検出するシステムの開発をはじめました。
認識したいものを教師データとしてAIに学習させることで、カメラ画角や環境光の認識精度への影響もパターンマッチに比べて少ないため認識精度が向上し、かつ高速に動作(画像の大きさにもよりますが20~30FPS)するため、リアルタイムでのインタフェース制作への応用を試みています。
上記の様な物体検出AIを利用したインタフェースをインスタレーション展示で導入したり、クライアントワークで実制作に応用した事例もすでに複数あります。
システム構成
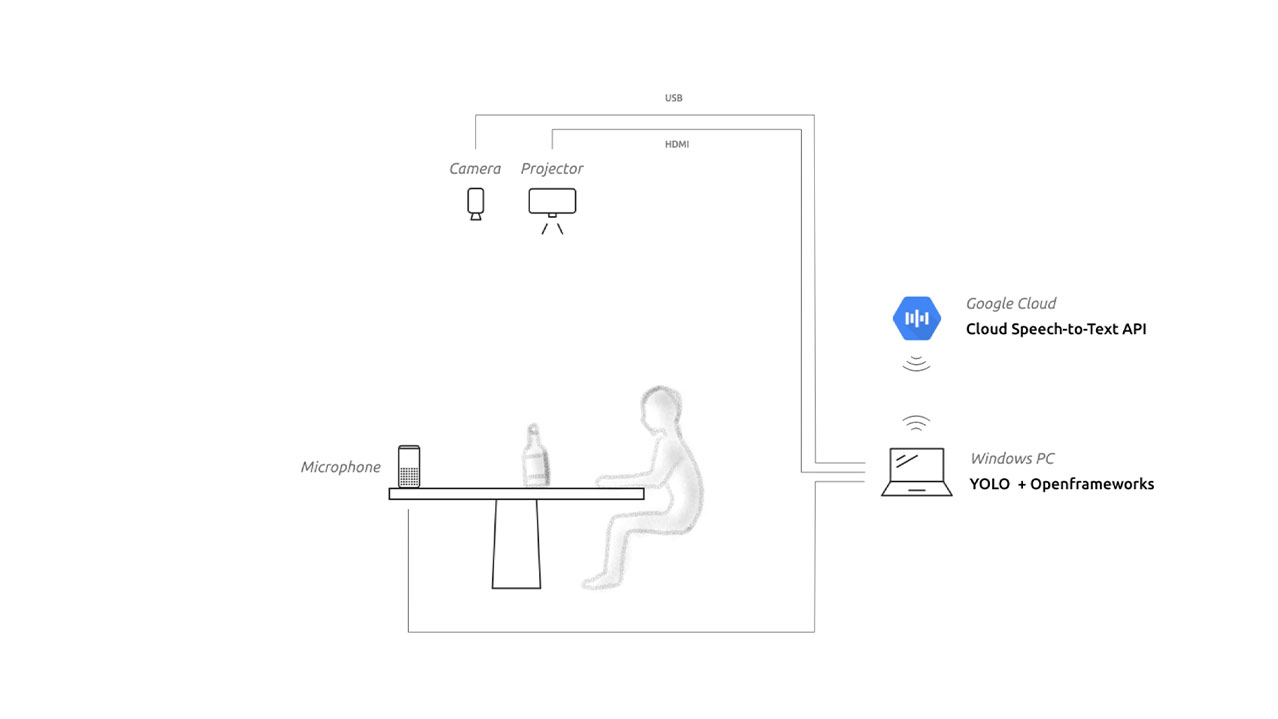
現状のシステムは、以下の手順で動作しています。
- カメラ撮影
- 撮影画像をAI(物体検出AIのYOLO)へ送信(Windowsマシン)
- 物体追跡アルゴリズムにより、各フレーム間のオブジェクトIDを定義
- AIからプロジェクション制御アプリへ対象物の座標を送信(上記と同じWindowsマシン内、openFrameworksで制作)
※このアプリで卓上へのマッピングも行っています。 - マイクからの音声をGoogle Cloud Speech-to-Textへ送信
- Google Cloud Speech-to-Text から戻ってきたテキストを解析
- テキスト内にトリガーとなるワードが含まれていた場合、対象物の位置に光のアニメーションをプロジェクターから投影
また、事前準備として以下のことを行っておく必要があります。
- a : 認識対象の画像を多方向から撮影
- b : aの画像を教師データとしてAIを学習させる
今回は、シーンを限定した環境での学習をさせています。実際の製品化するにあたっては、データオーギュメンテーションを行い周囲の環境に対するロバスト性を確保していくことが必要となります。(詳細は今後、記事化予定)
音声認識に関しては、今後の実験で、スマートスピーカーへ連動させるようなプロトタイプのアップデートを行っていきたいと考えています。
今後の展望
現状、カメラとプロジェクションによる構成になっていますが、スマートグラスなどでの活用も検討できる構成に進化させていきたいと考えています。
次回以降、更に実験の過程にあったトライ・アンド・エラーを紹介予定です。
N sketchは、テクノロジーとデザインを横断したものづくりを行う会社です。
心地の良い製品を具現化するために、エンジニアリングによる問題解決と感性に訴えかける動きや体験の作り込みを大事にしています。
Webサービス開発から、IoT製品、インスタレーション、研究開発など様々な案件を手掛けています。
新しい技術を試してみたいかた、課題をお持ちのかた、是非ご気軽にご相談ください。
弊社では、一緒に課題解決に取り組むメンバーを募集しています。
興味のある方はこちらをご覧ください。